GraphQL API
GraphQL APIは、AI MarketerのGraphQLプラグインを通じてcontent-typesと対話するためのクエリと変異を実行することができます。結果はフィルタリング、ソート、ページネーションが可能です。
GraphQL APIを使用するには、GraphQLプラグインをインストールしてください:
- Yarn
- NPM
yarn add @AI Marketer/plugin-graphql
npm install @AI Marketer/plugin-graphql
インストールが完了すると、GraphQL playgroundは/graphql URLでアクセス可能となり、対話的にクエリと変異を構築し、あなたのcontent-typesに特化したドキュメンテーションを読むことができます:
GraphQL APIはメディアのアップロードをサポートしていません。すべてのファイルのアップロードにはREST API POST /upload エンドポイントを使用し、返された情報をcontent typesにリンクするために使用します。メディアファイルのidを使用してupdateUploadFileとdeleteUploadFile変異を使用してアップロードしたファイルを更新または削除することはできます(メディアファイルに対する変異を参照)。
クエリ
GraphQLのクエリは、データを変更することなくフェッチするために使用されます。
content-typeがあなたのプロジェクトに追加されると、2つの自動生成されたGraphQLクエリがあなたのスキーマに追加されます。これらはcontent-typeの単数形と複数形のAPI IDに基づいて命名されます。以下に例を示します:
| Content-type display name | Singular API ID | Plural API ID |
|---|---|---|
| レストラン | restaurant | restaurants |
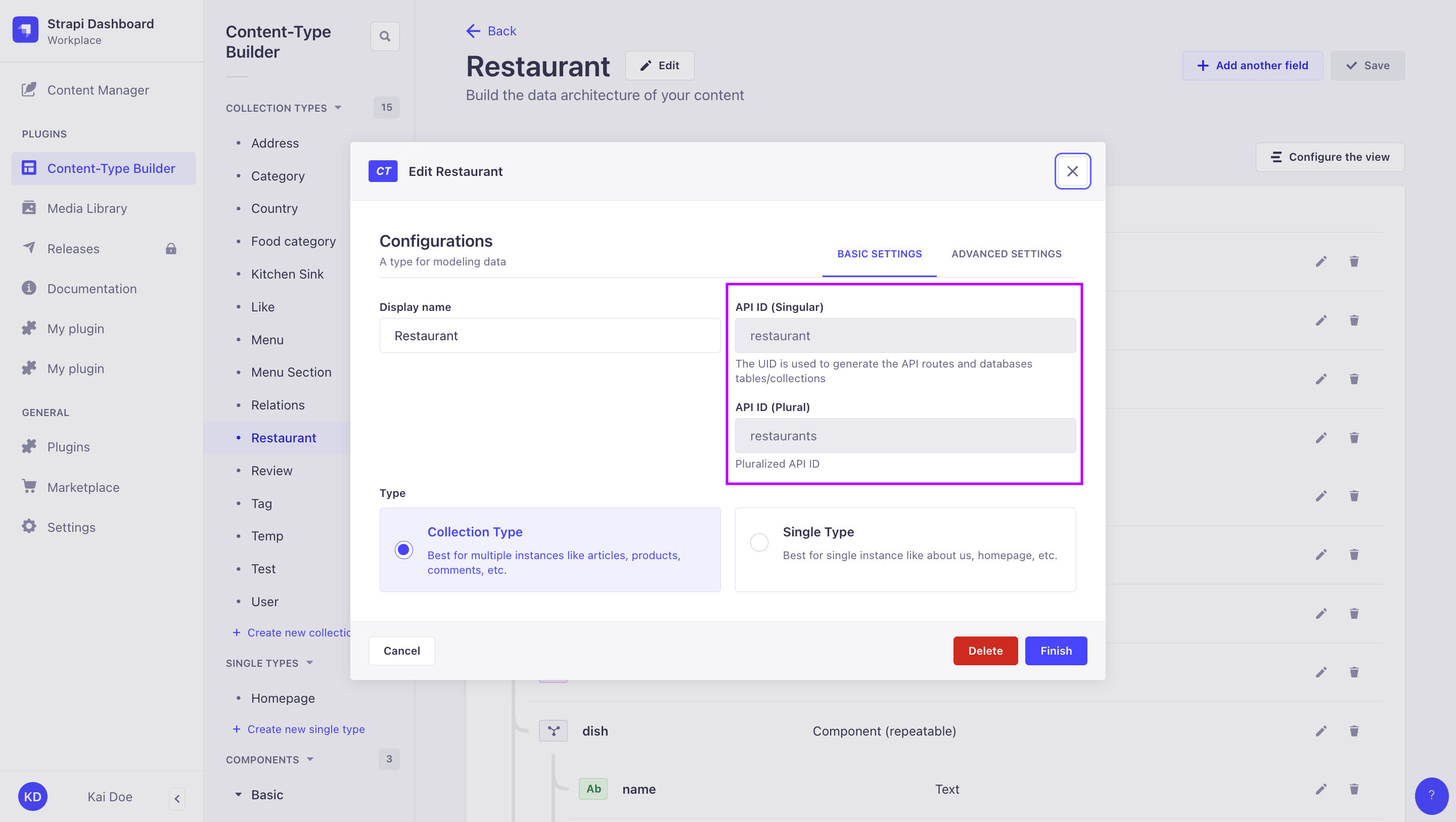
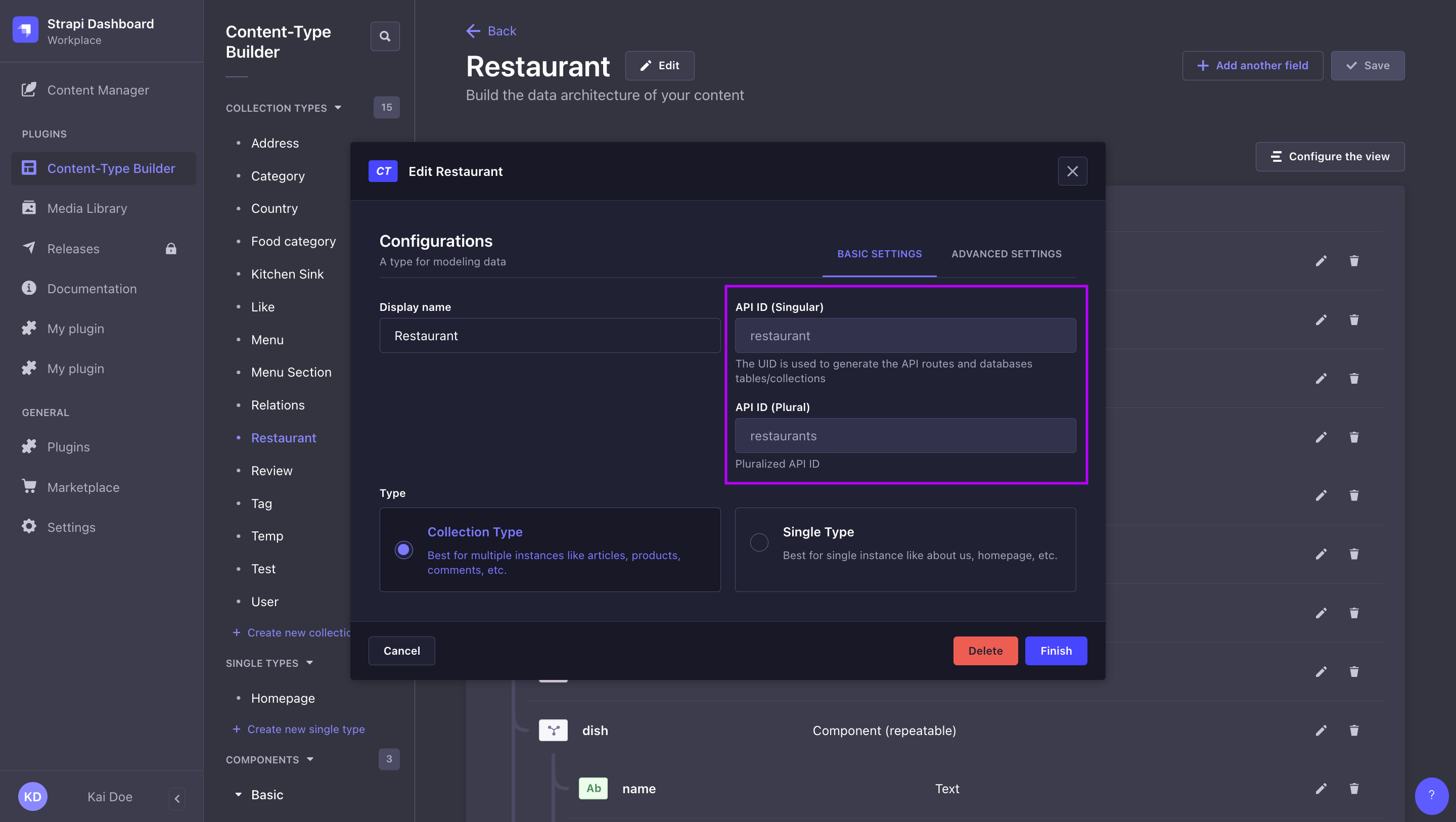
単数形のAPI ID vs. 複数形のAPI ID:
単数形のAPI IDと複数形のAPI IDの値は、Content-Type Builderでcontent-typeを作成する際に定義され、admin panelでcontent-typeを編集する際に見つけることができます(ユーザーガイドを参照)。content-typeを作成する際にカスタムAPI IDを定義することができますが、これらは後から変更することはできません。
単一のドキュメントをフェッチする
ドキュメント は、その documentId によって取得することができます。
{
restaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl") {
name
description
}
}
複数のドキュメントを取得する
複数のドキュメント を取得するためには、シンプルなフラットクエリまたは Relay-style クエリを使用することができます。
- Flat queries
- Relay-style queries
複数のドキュメントを取得するためには、以下のようなフラットクエリを使用することができます。
restaurants {
documentId
title
}
Relay-style クエリは、複数のドキュメントを取得し、メタ情報を返すために使用することができます。
{
restaurants_connection {
nodes {
documentId
name
}
pageInfo {
pageSize
page
pageCount
total
}
}
}
関連を取得する
フラットクエリまたは Relay-style クエリにおいて、関連データを含めて取得することができます。
- Flat queries
- Relay-style queries
次の例は、"Restaurant" コンテンツタイプのすべてのドキュメントを取得し、それぞれに対して、"Category" コンテンツタイプとの多対多の関係に対するいくつかのフィールドも返します。
{
restaurants {
documentId
name
description
# categories is a many-to-many relation
categories {
documentId
name
}
}
}
次の例は、Relay-style クエリを使用して "Restaurant" コンテンツタイプのすべてのドキュメントを取得し、各レストランに対して、"Category" コンテンツタイプとの多対多の関係に対するいくつかのフィールドも返します。
{
restaurants_connection {
nodes {
documentId
name
description
# categories is a many-to-many relation
categories_connection {
nodes {
documentId
name
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}
現時点では、pageInfo は最初のレベルのドキュメントに対してのみ動作します。AI Marketerの将来の実装では、関連に対して pageInfo を実装するかもしれません。
pageInfo の可能な使用例:
{
restaurants_connection {
nodes {
documentId
name
description
# 多対多の関連性
categories_connection {
nodes {
documentId
name
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}
{
restaurants_connection {
nodes {
documentId
name
description
# 多対多の関連性
categories_connection {
nodes {
documentId
name
}
# サポートされていません
pageInfo {
page
pageCount
pageSize
total
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}}
メディアフィールドの取得
メディアフィールドの内容は、他の属性と同様に取得します。
次の例では、"Restaurants" コンテンツタイプの各ドキュメントに添付された cover メディアフィールドの url 属性値を取得します:
{
restaurants {
images {
documentId
url
}
}
}
複数のメディアフィールドに対しては、フラットクエリまたはRelayスタイルのクエリを使用できます:
- フラットクエリ
- Relayスタイルクエリ
次の例では、"Restaurant" コンテンツタイプにある images 複数メディアフィールドからいくつかの属性を取得します:
{
restaurants {
images_connection {
nodes {
documentId
url
}
}
}
}
次の例では、"Restaurant" コンテンツタイプにある images 複数メディアフィールドからいくつかの属性を取得します。これはRelayスタイルのクエリを使用しています:
{
restaurants {
images_connection {
nodes {
documentId
url
}
}
}
}
現在、pageInfo はドキュメントに対してのみ機能します。AI Marketerの将来の実装では、メディアフィールドの _connection に対しても pageInfo が実装されるかもしれません。
コンポーネントの取得
コンポーネントの内容は、他の属性と同様に取得します。
次の例では、"Restaurants" コンテンツタイプの各ドキュメントに追加された closingPeriod コンポーネントの label、start_date、および end_date 属性値を取得します:
{
restaurants {
closingPeriod {
label
start_date
end_date
}
}
}
ダイナミックゾーンデータの取得
ダイナミックゾーンはGraphQLのunion typesなので、フィールドをクエリするためにはfragments(つまり、...onを使用して)を使用する必要があります。ここで、コンポーネント名(ComponentCategoryComponentnameの構文)を__typenameに渡します:
次の例では、"Default"コンポーネントカテゴリの"Closingperiod"コンポーネントからlabel属性のデータを取得します。これは、"dz"ダイナミックゾーンに追加することができます:
{
restaurants {
dz {
__typename
...on ComponentDefaultClosingperiod {
# コンポーネントの返す属性を定義
label
}
}
}
}
下書きまたは公開バージョンの取得
下書き&公開機能がコンテンツタイプに有効になっている場合、下書きまたは公開バージョンのドキュメントを取得するために、クエリにstatusパラメータを追加することができます。
query Query($status: PublicationStatus) {
restaurants(status: DRAFT) {
documentId
name
publishedAt # nullを返すべき
}
}
query Query($status: PublicationStatus) {
restaurants(status: PUBLISHED) {
documentId
name
publishedAt
}
}
ミューテーション
GraphQLのミューテーションは、データの変更(例:データの作成、更新、削除)に使用されます。
コンテンツタイプがプロジェクトに追加されると、ドキュメントの作成、更新、削除を行うための3つの自動生成されたGraphQLミューテーションがスキーマに追加されます。
例えば、"Restaurant"というコンテンツタイプの場合、以下のミューテーションが生成されます:
| ユースケース | 単数形のAPI ID |
|---|---|
| 新しい"Restaurant"ドキュメントの作成 | createRestaurant |
| 既存の"Restaurant"レストランの更新 | updateRestaurant |
| 既存の"Restaurant"レストランの削除 | deleteRestaurant |
新しいドキュメントの作成
新しいドキュメントを作成する際、data引数には、コンテンツタイプに特有の入力タイプが関連付けられます。
例えば、AI Marketerプロジェクトに"Restaurant"コンテンツタイプが含まれている場合、以下のようになります:
| ミューテーション | 引数 | 入力タイプ |
|---|---|---|
createRestaurant | data | RestaurantInput! |
次の例は、"Restaurant"コンテンツタイプの新しいドキュメントを作成し、そのnameとdocumentIdを返します:
mutation CreateRestaurant($data: RestaurantInput!) {
createRestaurant(data: {
name: "Pizzeria Arrivederci"
}) {
name
documentId
}
}
新しいドキュメントを作成すると、documentIdが自動的に生成されます。
ミューテーションの実装では、リレーション属性もサポートされています。例えば、新しい"Category"を作成し、多くの"Restaurants"(それぞれのdocumentIdを使用して)をそれに関連付けるクエリを以下のように書くことができます:
mutation CreateCategory {
createCategory(data: {
Name: "Italian Food"
restaurants: ["a1b2c3d4e5d6f7g8h9i0jkl", "bf97tfdumkcc8ptahkng4puo"]
}) {
documentId
Name
restaurants {
documentId
name
}
}
}
あなたのコンテンツタイプに対して国際化(i18n)機能が有効化されている場合、特定のロケール向けのドキュメントを作成することができます(詳細はi18nドキュメンテーションを参照してください)。
既存のドキュメントの更新
既存のドキュメントを更新する際には、documentIdと新しいコンテンツを含むdataオブジェクトを渡します。data引数は、あなたのコンテンツタイプに特有の入力タイプを持つでしょう。
例えば、あなたのAI Marketerプロジェクトが"Restaurant"コンテンツタイプを含んでいる場合、以下のようになるでしょう:
| ミューテーション | 引数 | 入力タイプ |
|---|---|---|
updateRestaurant | data | RestaurantInput! |
例えば、以下の例では"Restaurants"コンテンツタイプから既存のドキュメントを更新し、新しい名前を付けています:
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!) {
updateRestaurant(
documentId: "bf97tfdumkcc8ptahkng4puo",
data: { name: "Pizzeria Amore" }
) {
documentId
name
}
}
あなたのコンテンツタイプに対して国際化(i18n)機能が有効化されている場合、特定のロケール向けのドキュメントを作成することができます(詳細はi18nドキュメンテーションを参照してください)。
関係の更新
documentIdまたはdocumentIdの配列(関係のタイプによる)を渡すことで、関係的な属性を更新することができます。
例えば、以下の例では"Restaurant"コンテンツタイプからのドキュメントを更新し、categories関係フィールドを通じて"Category"コンテンツタイプからのドキュメントに関係を追加します:
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!) {
updateRestaurant(
documentId: "slwsiopkelrpxpvpc27953je",
data: { categories: ["kbbvj00fjiqoaj85vmylwi17"] }
) {
documentId
name
categories {
documentId
Name
}
}
}
ドキュメントの削除
ドキュメントを削除するには、そのdocumentIdを渡します:
mutation DeleteRestaurant {
deleteRestaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl") {
documentId
}
}
あなたのコンテンツタイプに対して国際化(i18n)機能が有効化されている場合、ドキュメントの特定のローカライズバージョンを削除することができます(詳細はi18nドキュメンテーションを参照してください)。
メディアファイルに対するミューテーション
現在、メディアフィールドに対するミューテーションは、メディアファイルの一意の識別子としてAI Marketer v4のidを使用し、AI Marketer 5のdocumentIdは使用していません。
メディアフィールドのミューテーションはファイルのidを使用します。しかし、AI Marketer 5のGraphQL APIのクエリでは、もはやidは返されません。メディアファイルのidは次のように見つけることができます:
- 管理パネルからのメディアライブラリで、
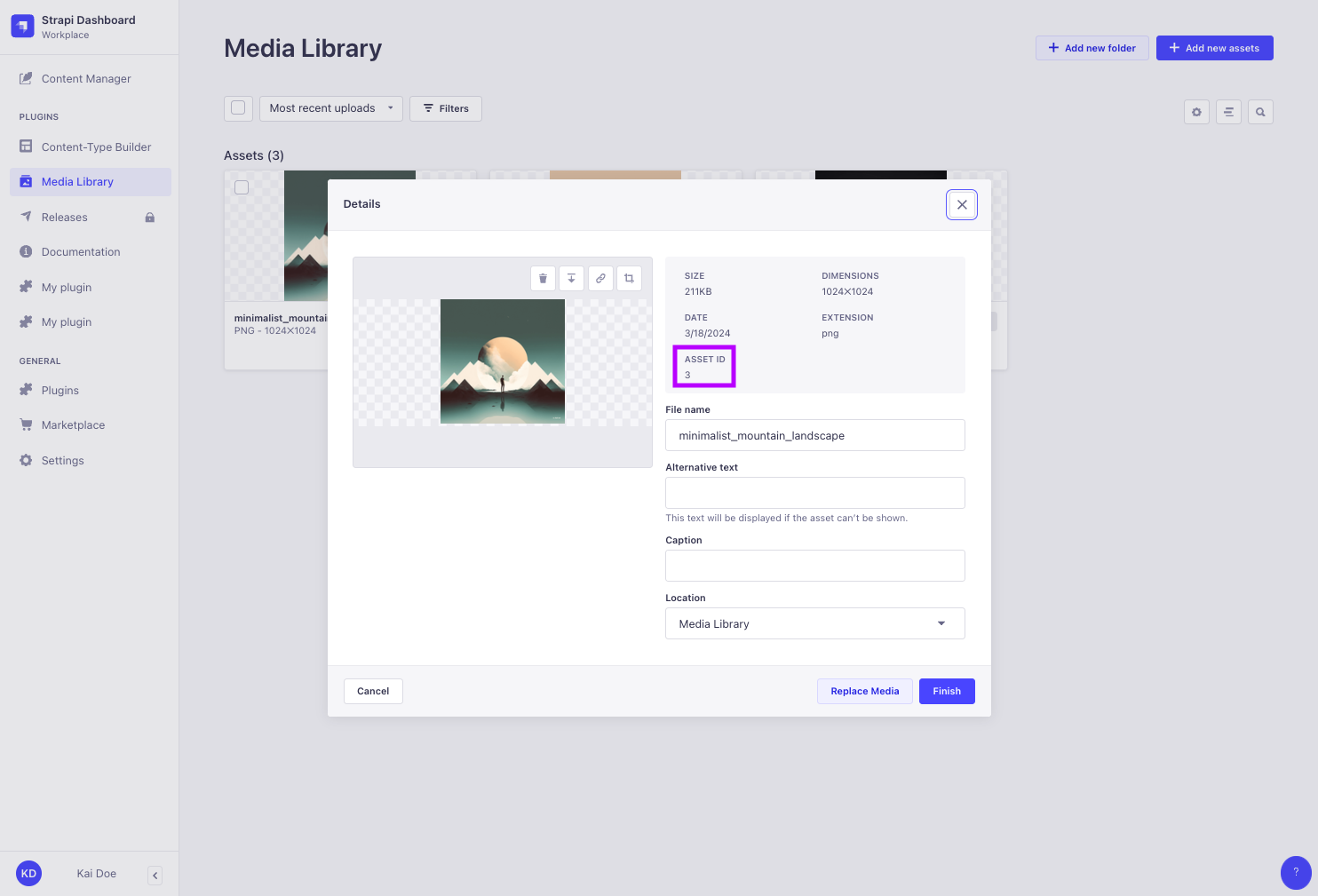
- または、REST APIの
GETリクエストを送信してメディアファイルを取得します。なぜなら、現在のREST APIのリクエストはメディアファイルのidとdocumentIdの両方を返すからです。
アップロードしたメディアファイルの更新
アップロードしたメディアファイルを更新する際には、メディアの id ( documentId ではない)と新しい内容を含む info オブジェクトを渡します。 info 引数は、メディアファイルに特化した入力タイプを持っています。
例えば、あなたのAI Marketerプロジェクトが "Restaurant" コンテンツタイプを含んでいる場合、以下のようになります:
| ミューテーション | 引数 | 入力タイプ |
|---|---|---|
updateUploadFile | info | FileInfoInput! |
例えば、以下の例では id が3のメディアファイルの alternativeText 属性を更新します:
mutation Mutation($updateUploadFileId: ID!, $info: FileInfoInput) {
updateUploadFile(
id: 3,
info: {
alternativeText: "New alt text"
}
) {
documentId
url
alternativeText
}
}
アップロードのミューテーションがアクセス禁止エラーを返す場合は、Uploadプラグインの適切な権限が設定されていることを確認してください(ユーザーガイドを参照)。
アップロードしたメディアファイルの削除
アップロードしたメディアファイルを削除する際には、メディアの id ( documentId ではない)を渡します。
mutation DeleteUploadFile($deleteUploadFileId: ID!) {
deleteUploadFile(id: 4) {
documentId # return its documentId
}
}
アップロードのミューテーションがアクセス禁止エラーを返す場合は、Uploadプラグインの適切な権限が設定されていることを確認してください(ユーザーガイドを参照)。
フィルタ
クエリは次の構文を持つ filters パラメータを受け入れることができます:
filters: { field: { operator: value } }
複数のフィルタを組み合わせることができ、また、論理演算子(and, or, not)も使用でき、オブジェクトの配列を受け入れます。
以下の演算子が利用可能です:
| 演算子 | 説明 |
|---|---|
eq | 等しい |
ne | 等しくない |
lt | より小さい |
lte | 以下 |
gt | より大きい |
gte | 以上 |
in | 配列に含まれる |
notIn | 配列に含まれない |
contains | 含む、大文字小文字を区別 |
notContains | 含まない、大文字小文字を区別 |
containsi | 含む、大文字小文字を区別しない |
notContainsi | 含まない、大文字小文字を区別しない |
null | nullである |
notNull | nullでない |
between | ~の間にある |
startsWith | ~で始まる |
endsWith | ~で終わる |
and | 論理 and |
or | 論理 or |
not | 論理 not |
{
restaurants(
filters: {
averagePrice: { lt: 20 },
or: [
{ name: { eq: "Pizzeria" }}
{ name: { startsWith: "Pizzeria" }}
]}
) {
documentId
name
averagePrice
}
}
ソート
クエリは次の構文を持つ sort パラメータを受け入れることができます:
- 単一の値に基づいてソートするには:
sort: "value" - 複数の値に基づいてソートするには:
sort: ["value1", "value2"]
ソート順は :asc(昇順、デフォルト、省略可能)または :desc(降順)で定義できます。
{
restaurants(sort: "name") {
documentId
name
}
}
{
restaurants(sort: "averagePrice:desc") {
documentId
name
averagePrice
}
}
{
restaurants(sort: ["name:asc", "averagePrice:desc"]) {
documentId
name
averagePrice
}
}
ページネーション
Relay-style クエリは pagination パラメータを受け入れることができます。結果はページまたはオフセットでページネーションできます。
ページネーション方法は混在させることはできません。常に page と pageSize または start と limit を使用してください。
ページによるページネーション
| パラメータ | 説明 | デフォルト |
|---|---|---|
pagination.page | ページ番号 | 1 |
pagination.pageSize | ページサイズ | 10 |
{
restaurants_connection(pagination: { page: 1, pageSize: 10 }) {
nodes {
documentId
name
}
pageInfo {
page
pageSize
pageCount
total
}
}
}
オフセットによるページネーション
| パラメーター | 説明 | デフォルト | 最大値 |
|---|---|---|---|
pagination.start | 開始値 | 0 | - |
pagination.limit | 返すエンティティの数 | 10 | -1 |
{
restaurants_connection(pagination: { start: 10, limit: 19 }) {
nodes {
documentId
name
}
pageInfo {
page
pageSize
pageCount
total
}
}
}
pagination.limitのデフォルト値と最大値は、graphql.config.defaultLimitとgraphql.config.maxLimitのキーを使って./config/plugins.jsファイルで設定できます。